

Machine learning platforms are a must-have for financial institutions to be competitive in the digital era. The good news for banks is that machine learning components are readily available through open source libraries and technologies. The bad news, however, is that just because the components are available it does not mean that building and deploying a machine learning platform will happen overnight.
As banks pursue machine learning investments as part of their fraud prevention and detection strategies, it’s important to move beyond the hype and to distinguish machine learning reality from perceptions. Below are five common misconceptions about machine learning banks should consider before they build their own machine learning platform.
Misconception 1. I have the parts, I can build the whole on my own

One of the biggest misconceptions is that the process of building a machine learning platform will be easy. With so many open source libraries available, it can be tempting to think that you can simply build a machine learning platform and craft algorithms on your own. But this is a risky approach and what you ultimately build might not work as you had expected.
Imagine you want a car. You could buy the engine from one vendor, the wheels from another, and so on. Then all you do is put it together, right? Not so fast. Having all the required parts to build a car doesn’t necessarily mean that the final product you build will be a safe and reliable vehicle to put on the road. You can imagine how frustrating it would feel to invest so much time and resources into building something that isn’t roadworthy.
Building a machine learning platform can be just as complicated. Just as a car has to be street legal and ready for various road conditions, weather, and unpredictable events, machine learning platforms must be able to handle any changes that come their way, including changes that impact large volumes of data. Feedzai’s machine learning platform relies on components from 132 tools and libraries. But the platform is more than the sum of our parts. The platform you build must meet certain requirements, just as any car you build would need to meet existing safety standards.
Misconception 2. Complete means the same thing to everybody.
Complete might seem like a straightforward word. But believe it or not, the tech industry doesn’t always agree on the definition. An organization that is not careful about how it defines “complete” could misconstrue its offering as a complete solution when in reality it is not.
To understand why there is disagreement over the term, let’s look at how the modeling process works. As illustrated below, the platform first receives data, often from multiple datasets. Then it stratifies data, performs feature engineering, and builds a machine learning model. From there, the model can be evaluated and adjusted by the data science team as needed. The feedback can be automated to improve the model’s self-learning capabilities.
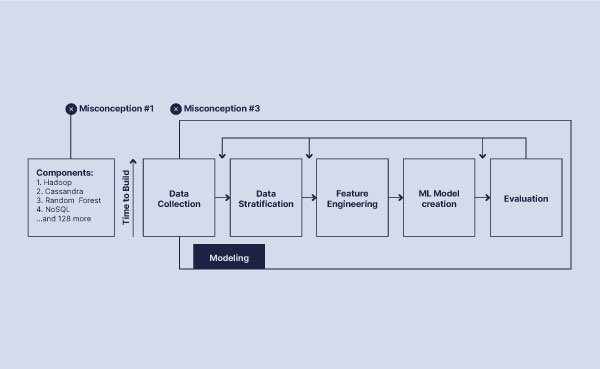
Here’s where the definition of “complete” gets murky. Some organizations only offer parts of this process. But this piecemeal process can result in incomplete solutions, especially if you want to tackle specific use cases like fraud detection and prevention.
Having a truly “complete” solution in place is critical when it comes to tackling fraud prevention and detection. Some out-of-the-box solutions will give you the ability to perform feature engineering. However, the question to ask is, which features will you be able to engineer? For example, most out-of-the-box solutions don’t allow you to build in-depth customer profiles. Fraud detection is a very niche function that requires specific components. For instance, it’s important to ask if the platform will be able to report results both per transaction and per customer. These insights are critical to building deep knowledge of typical consumer behavior. Many open source components are domain agnostic and not built for fraud detection. This can make it challenging to build a truly “complete” fraud detection solution.
To say your solution is “complete” you should make sure that it covers the full set of steps in the data science loop.
Misconception 3. I can build this in a year

Having a clear understanding of the term “complete” solves only one problem. Organizations also tend to underestimate how long it will take to integrate various components into a whole. Connecting the different machine learning phases into a single, unified platform is challenging and can be time-consuming.
A U.S.-based issuer didn’t realize how long the effort would take. They purchased a machine learning platform with the goal of achieving the final two steps, machine learning model building and evaluation. From there, they believed they could integrate the previous steps – data collection, data stratification, and feature engineering – by themselves in less than a year. Years later, they are still short of a complete machine learning platform.
The issuer’s experience should serve as a cautionary tale for other organizations. While there are several open source tools available, none exist that can easily piece together the different data science phases into a single solution. The process takes time.
Misconception 4. What works in the sandbox will work in the field

Misconceptions about how easy it is to shift machine learning models to a live environment is another point that organizations often fail to comprehend. Training data models can take time. So can adjusting models once they have been deployed to the field. Organizations need to understand that while it can take a long time to create and build a system for modeling and data analytics, it can also take a long time to shift the model out of a sandbox environment and into production.
Once the model moves into production, organizations might be surprised when it doesn’t behave as expected. A business that processes 10 million transactions per month will need a platform capable of processing large volumes of real-time data. The platform will also need to calculate the features you built, years of historical data, and adjust to new sources of big data. As we saw from the COVID-19 pandemic and resulting lockdowns, unexpected changes in consumer behaviors can throw a machine learning model off. That’s why it’s important to invest in an agile solution that can support multiple, custom models, and that can respond to new developments and add new models once new fraud trends emerge.
It’s easy to underestimate the range of elements that only become relevant once a model goes live. Factors that often get overlooked and that cannot be fixed once in production include low latencies (as in taking up to 10 milliseconds per event) at high throughputs (in which large amounts of transactions are processed in parallel).
Organizations will also need to keep tabs on their model once it leaves the sandbox environment and have a plan in place in case something unexpected happens. It’s important for organizations to factor monitoring and observability into their workflows in order to determine if a problem has arisen once the model goes live. Having a failover mechanism in place will help organizations determine how to move forward when something goes wrong.
Inevitably, human intervention will be needed to change an organization’s live model to respond to new circumstances, such as increased fraud activity or the emergence of new fraud patterns. If this happens, organizations can avoid interrupting their workflows using “shadow models.” Shadow models refer to models that work in the background using the same transaction data as a live model while their improvements are being validated. When organizations want to update their live models, data scientists need to replace them with an upgraded shadow model without experiencing hiccups or downtime.
Misconception 5. Metrics are not the end, just part of the journey
Once all the previous misconceptions are addressed and an FI can accurately call its machine learning process “complete,” only a small group of platforms will remain. The question then turns to what sets the platforms apart.
Some platforms will boast about reducing false positives or being able to process a high rate of transactions per second. However, these are table stakes and the real differentiators will lie in the platform’s capabilities. It’s important to ask if the platform offers explainable AI or that adds a human-readable semantic layer instead of a black box solution that hides the ML model’s processing. Human-friendly explanations – including visual analysis tools – put human beings back in charge of the machines they monitor and in control of the decision-making process.
Key Takeaways
Building a machine learning platform is a complicated process and can take a long time. It’s important to remember that the model is likely to behave very differently in production than it did in the sandbox environment where it was developed. The platform should provide users with user-friendly explanations of its findings. Understanding these common myths and misconceptions about machine learning is an important step in building a platform successfully and moving it into production.
Download the eBook Demystifying Machine Learning to learn more about machine learning’s evolution and how it can be put to use at your own organization.
Share this article:
Related Posts

0 Comments5 Minutes
A Global Elder Fraud Epidemic: Exclusive Feedzai Research
Digital connections have become lifelines for our senior citizens. But the digital realm,…

0 Comments9 Minutes
A New Account Fraud Solution to Block Fraud at Stage 1
The account opening stage is arguably the most crucial point in a bank's customer…

0 Comments16 Minutes
Using Fraud Analytics to Stay Ahead of Criminals
As if the battle against fraud wasn’t complicated enough, merchants have to contend with…