

Demystifying Machine Learning for Banks is a five-part blog series that details how the machine learning era came to be, explains why machine learning is the key artificial intelligence technology, outlines how machine learning works, and explains how to put all this information together in the data science loop. This is the first post in the series.
Why This is the Machine Learning Era for Banks
People have been saying it for a while. “Artificial intelligence (AI) has arrived!” Well, AI turned 70 this year. It’s not new. We’ve witnessed a unique moment in history: AI’s graduation from the laboratory to the full market.
AI used to belong to the halls of academic research and the R&D bunkers of multibillion-dollar corporations. Now, AI is affordable and attainable, signaling a radically transformed landscape that changes the way we live, work, and pay. The widespread adoption of AI marks the birth of something that’s been gestating for decades.
But what makes this moment so significant? In a word: convergence. Distinct technological strands, developed over the last 15 years, have come together in a perfect storm.
First came the mobile era, which placed powerful computers and sensors in our pockets. Next came big data. The exponential growth of powerful computers and sensors gave rise to the ability to process and store unprecedented amounts of data. Sometime around 2010, our world produced information surpassing one zettabyte. To understand just how “big” data is, think of it like this: if your cup of coffee held a gigabyte, you’d need The Great Wall of China to store a zettabyte. And by 2020, that number will increase 44 times over, from one zettabyte of data produced globally to 44 zettabytes.
This advent of big data happened to coincide with the advent of better computing, better algorithms, and new AI-focused organizations, allowing us to take this data and turn it into something even better: meaning.
This brings us to machine learning. Later in this series, we’ll look at how machine learning works and how it can work for you. But first, let’s take a closer look at all the ingredients that got us here.
Affordable parallel computing
First, it is becoming exponentially less expensive to compute. In 2004, Google introduced MapReduce, a technique for processing massive amounts of data using many computers working in parallel. Google’s big idea was to go down-market, not up-market, with its hardware. While other companies were using expensive, top-of-the-line supercomputers, workstations, and mainframes, Google was using the cheapest computer parts they could find. When one piece of equipment broke, as often happened, parallel processing meant another computer could pick up right where the old one left off. Open-sourced versions of this technology spread and drove down computing costs.
Faster processing
A decade ago, the modern Graphics Processing Unit (GPU) began to evolve. GPUs have thousands of cores, as opposed to Central Processing Units (CPUs), which only have a few cores. Originally, GPUs were designed to create graphics, but innovators began to exploit their numerous cores for processing parallel streams of data at the same time. By combining the strengths of GPUs and CPUs, which excel in different kinds of tasks, programmers milked the most computing power out of both, speeding up applications a hundred times over.
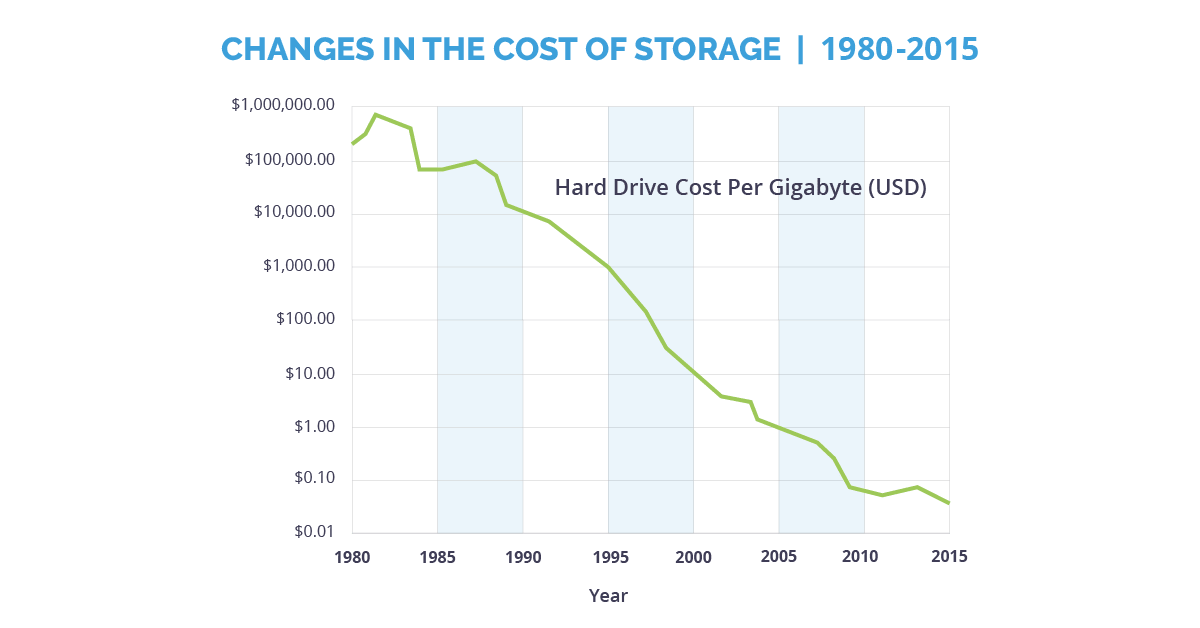
Cheaper data storage
While computer processing was going up, the cost of storing data was going down — way down. In 2008, the major players in tech created databases or storage solutions that didn’t require SQL queries, which can take a long time to execute. These new systems were named NoSQL, or “not only SQL,” and they replaced older relational databases to store things that weren’t practical to store before: massive social networking text files, satellite images, and other kinds of enormous data files.
Big data in a connected world
In the thousands of years between the dawn of humanity and the year 2003, humans created five exabytes of data. Now we create that much data every day. And our “data footprint” only continues to double every year. Even more important than the sheer volume of data is its interconnectedness. These billions and billions of interlinked data points are providing a more unified view of reality.
Better, more accessible algorithms
In the 2000s, new and better machine learning algorithms and techniques would turbocharge the predictive power of machine learning models. With esoteric names like Random Forests and Deep Learning, these new algorithms made machine learning models better at doing their job, while producing valuable insights that we could have never found on our own.
It’s no wonder that by late 2016, machine learning had reached the top of the “hype cycle,” a measure of the diffusion of new technologies into mainstream business. In other words, machine learning is moving from a specialty to a utility. Leveraging its power is like turning the lights on.
Because machine learning can solve problems that were previously unsolvable, organizations that have machine learning platforms vastly outperform organizations that don’t. And that makes this an arms race.
This four-part blog series will explain how machine learning works and illustrate how it can be deployed inside financial institutions to thwart threats and save millions.
The Takeaway
In essence, it became possible to say that machine learning has developed “economies of scale” to the stage where systems can actually “learn” and “predict.” Machine learning is becoming affordable, not just for companies like Google, but also for enterprises looking to transform their vast amounts of dormant or siloed data into insights and predictions.
Want to learn more about machine learning? Download the ebook, Operationalizing Machine Learning for Fraud today.
Share this article:
Related Posts

0 Comments10 Minutes
Boost the ESG Social Pillar with Responsible AI
Tackling fraud and financial crime demands more than traditional methods; it requires the…

0 Comments8 Minutes
Enhancing AI Model Risk Governance with Feedzai
Artificial intelligence (AI) and machine learning are pivotal in helping banks and…

0 Comments14 Minutes
What Recent AI Regulation Proposals Get Right
In a groundbreaking development, 28 nations, led by the UK and joined by the US, EU, and…