

Demystifying Machine Learning for Banks is a five-part blog series that details how the machine learning era came to be, explains why machine learning is the key artificial intelligence technology, outlines how it works, and explains how to put all this information together in the data science loop. This article is the third post in the series.
Traditional computing relies on software developers creating a series of rules or programs that allow computers to process raw input data into useful output. This approach suffices for solving problems that are well-defined and procedural, such as calculating interest on a loan or displaying a web page.
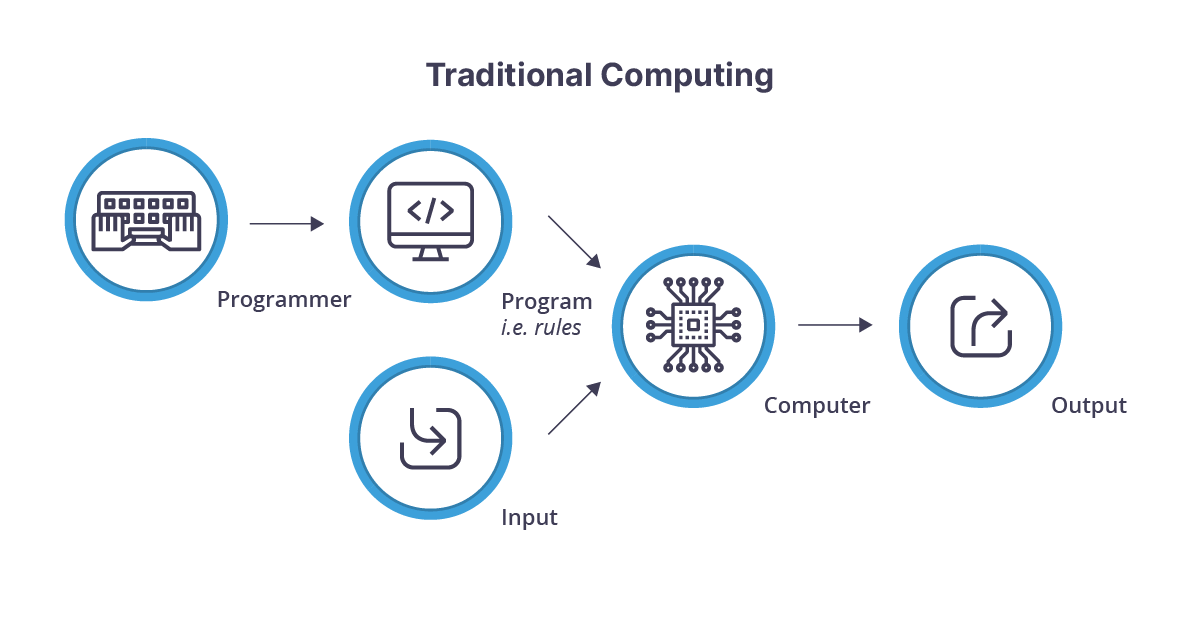 Machine learning, by contrast, excels at solving problems where the “problem space” cannot be expressed easily as rules. For example, given enough data, machine learning can succeed with high accuracy at complex cognition tasks like recognizing a picture of a face, identifying potential fraud amongst transactions, or making a personalized recommendation.
Machine learning, by contrast, excels at solving problems where the “problem space” cannot be expressed easily as rules. For example, given enough data, machine learning can succeed with high accuracy at complex cognition tasks like recognizing a picture of a face, identifying potential fraud amongst transactions, or making a personalized recommendation.
Imagine creating a rule that can identify the number “7”. You’d think it’d be easy to identify 7: two strokes, one across, one going down at a slope. But, there are many ways to write a 7, with different thickness, extra strokes, and lines that don’t connect. And these are just computer fonts! If you consider “7” written by human hands, as the post office does when it parses written addresses, the variations are even more drastic. And then there is a photo of the “7”. In the photographic scenario, you also must consider the angle of light, the digit in context with other symbols, and the contrast against hard-to-read backgrounds.
Can a rule describe the number 7?
 For a person, even a young child, it’s no trouble to identify these numbers above, but it’s hard to come up with rules that can do it. One challenge is to create a rule that differentiates 7 with these different, but similar shapes, such as a coffee mug handle.
For a person, even a young child, it’s no trouble to identify these numbers above, but it’s hard to come up with rules that can do it. One challenge is to create a rule that differentiates 7 with these different, but similar shapes, such as a coffee mug handle.
The ability to identify all the different forms of “7” allows machine learning to succeed where rules fail. A human doesn’t write a machine learning program line-by-line. Instead, a program (what we call the Machine Learning algorithm) uses example data to create a ‘model’ that is able to solve this task. In this scenario, example data would correspond to different images and a label saying whether they represent a “7” or not. After its creation, the ‘model’ (equivalent to a ‘program’) can take in new input data and convert it into useful output. We can see a Machine Learning algorithm as a program that creates new programs.
The application of massive computing power and innovation in such algorithms, such as random forests, deep learning, gradient boosting, etc., enables powerful new technologies such as Amazon’s Alexa and Google’s self-driving car. These technologies would not be possible under the old paradigm of humans writing rule-based programs for such systems.
The Two Phases of Machine Learning
The machine learning process consists of two main phases: training the system and predicting real data. These main phases represent parts of an iterative methodology of applying machine learning techniques called the ‘data science loop’. Data scientists or analysts can repeat the data science loop as often as needed to incrementally improve the accuracy of their system.
Phase 1: Machine Learning Model Training
In the training phase, a data scientist supplies some input data and describes the expected output using historical information. The computer, leveraging the machine learning algorithm, uses this information to build a statistical model, which represents the patterns that it detected in the training input data. For example, training data could be a large set of credit card transactions, some fraudulent, some non-fraudulent.
The data could include many relevant data points that lend accuracy to a model. In the context of a payment transaction, these could be transaction time, location, merchant, amount, whether the cardholder was present, and the type of terminal used to accept the transaction. These measurable attributes in the data are known as features. They can include attributes that are found in the data in its native form, as well as computed features such as average transaction amount for a specific account or total number of transactions in the past twenty-four hours. .
The process of selecting the most appropriate features for the model is where the machine plugs back into the human. The process is called “feature selection,” and it is one of the most important parts of developing an effective and accurate model.
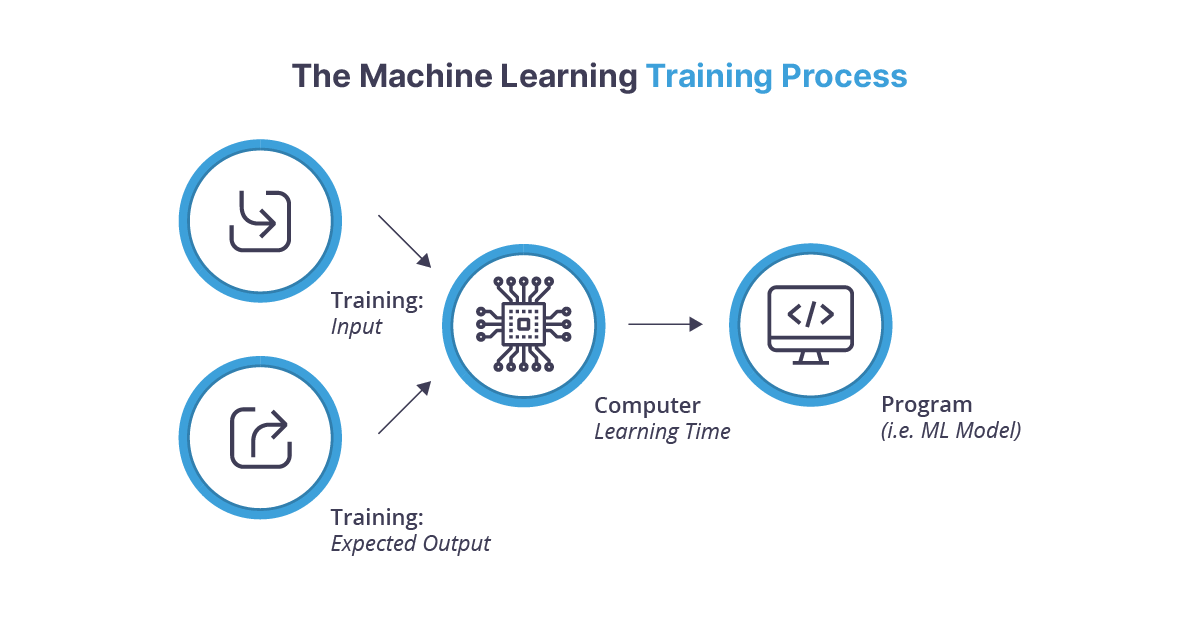 Machine learning can be used to create models that are capable of expressing much more sophisticated outputs than a set of human-programmed rules could ever devise. Machine learning can also be trained to avoid biases that a human can’t quite shed. If you have a suitable software platform, machine learning models can also be re-trained, updated, and deployed to a production environment in a matter of minutes.
Machine learning can be used to create models that are capable of expressing much more sophisticated outputs than a set of human-programmed rules could ever devise. Machine learning can also be trained to avoid biases that a human can’t quite shed. If you have a suitable software platform, machine learning models can also be re-trained, updated, and deployed to a production environment in a matter of minutes.
Phase 2: Evaluation
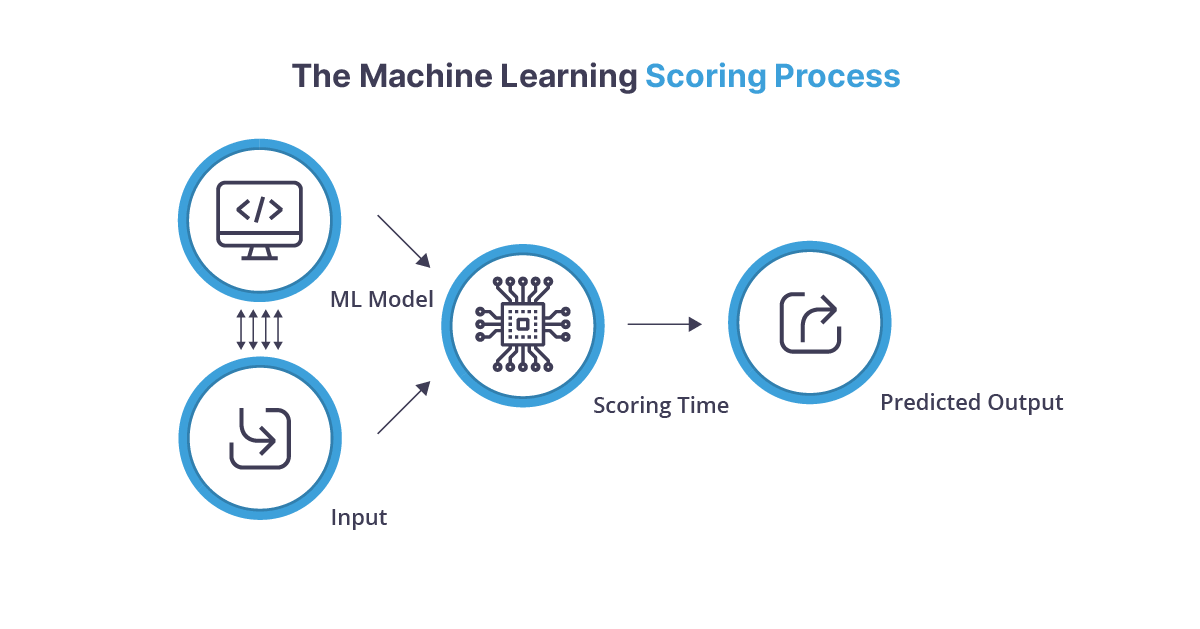 In the evaluation (or real-world) phase, the machine learning system uses the model that it developed to “predict” the output for real-world input data using the “rules” that the model contains. In this way, it can process large volumes of data extremely quickly — indeed, often in real-time.
In the evaluation (or real-world) phase, the machine learning system uses the model that it developed to “predict” the output for real-world input data using the “rules” that the model contains. In this way, it can process large volumes of data extremely quickly — indeed, often in real-time.
When a classification model processes data, it produces a probability that the input data matches one of the classes from the training data. It thus produces a prediction or correlation rather than a statement of causality. These patterns that machine learning systems can see are often so granular that no human could ever catch them.
Key Takeaways
Consider a system configured for a financial institution’s credit card-processing infrastructure. The terminal passes transaction data into the machine learning system. The machine learning system then analyzes the transaction against the model that it has been trained on. Since the system can use a vast trove of historical data to build a picture of “usual” legitimate activity, it can build a nuanced assessment of whether the activity in question fits past behavior.
Share this article:
Related Posts

0 Comments10 Minutes
Boost the ESG Social Pillar with Responsible AI
Tackling fraud and financial crime demands more than traditional methods; it requires the…

0 Comments8 Minutes
Enhancing AI Model Risk Governance with Feedzai
Artificial intelligence (AI) and machine learning are pivotal in helping banks and…

0 Comments14 Minutes
What Recent AI Regulation Proposals Get Right
In a groundbreaking development, 28 nations, led by the UK and joined by the US, EU, and…