

Demystifying Machine Learning for Banks is a five-part blog series that details how the machine learning era came to be, explains why machine learning is the key artificial intelligence technology, outlines how machine learning works, and explains how to put all this information together in the data science loop. This article is the fifth and final post in the series.
Fraud detection allows banks to reduce their systemic exposure to it, but that’s easier said than done. Fraudsters use new technologies to continually innovate types of fraud attacks, which means banks must also continuously innovate to stay one step ahead of criminals. In addition to predicting fraudsters’ next schemes, banks must also remain flexible enough to comply with ongoing regulatory changes — and the consequent costs of mitigating them.
Machine learning excels at providing flexibility while also managing the operational costs associated with fraud detection and prevention. To understand the unique benefits machine learning provides, we must examine the particular challenges that fraud detection presents to financial institutions.
Moving from reactive to proactive fraud detection
Fraud patterns change rapidly, and financial institutions struggle to adapt to new threats. Rules-based approaches to fraud detection rely on identifying patterns of known attacks and addressing them head-on. The problem with this approach is that it has financial institutions addressing yesterday’s threat while leaving them open to today’s new wave of attacks. It’s an unfair playing field; criminals can adapt their tactics every day, but it can take three to six months for conventional fraud-detection products to catch up. By contrast, fraud-detection systems based on machine learning can recognize suspicious patterns in an instant, even when the context changes.
Chasing the long tail
Traditional rules-based approaches to fraud detection face a further threat: there are too many unique fraud cases — fraud schemes can differ across geography, merchant category group, payment method, among many others. Additionally, despite the high financial and reputational impact of fraud, the numerical incidence per fraud scheme is relatively low. The incidence rate is also spiky across time, with sporadic and seemingly unpredictable variations.
Further, each unique case of fraud may not share a consistent set of characteristics, and with traditional approaches, the result is either failed identification or over-flagging. As a result, financial institutions estimate that manual review processes account for almost 25% of the total cost of fraud prevention — even more significant than physical security measures.
By building models that are able to automatically learn these real-world complexities of fraud, machine learning systems don’t just greatly improve detection rates, they reduce manual reviews as well. This provides a significant advantage when you consider the cost and scaling problems associated with traditional approaches.
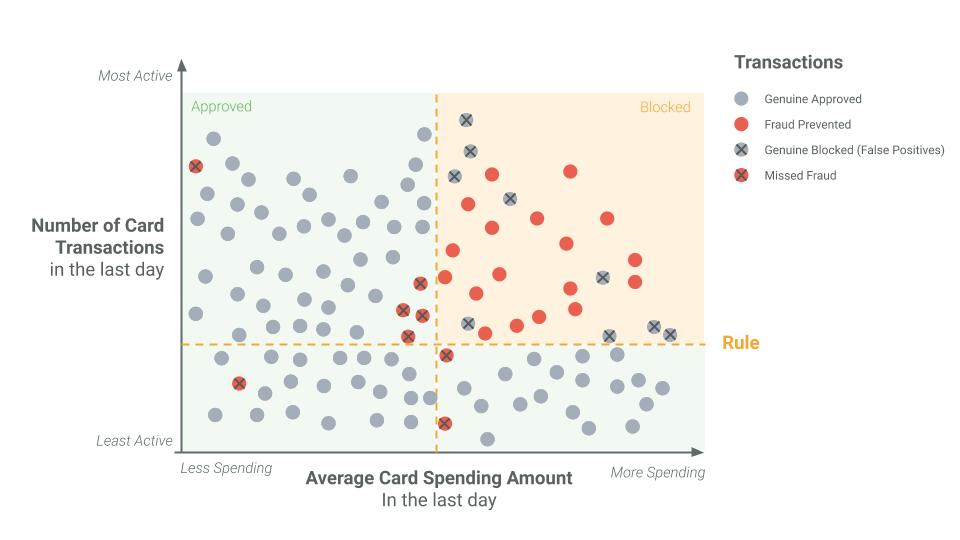
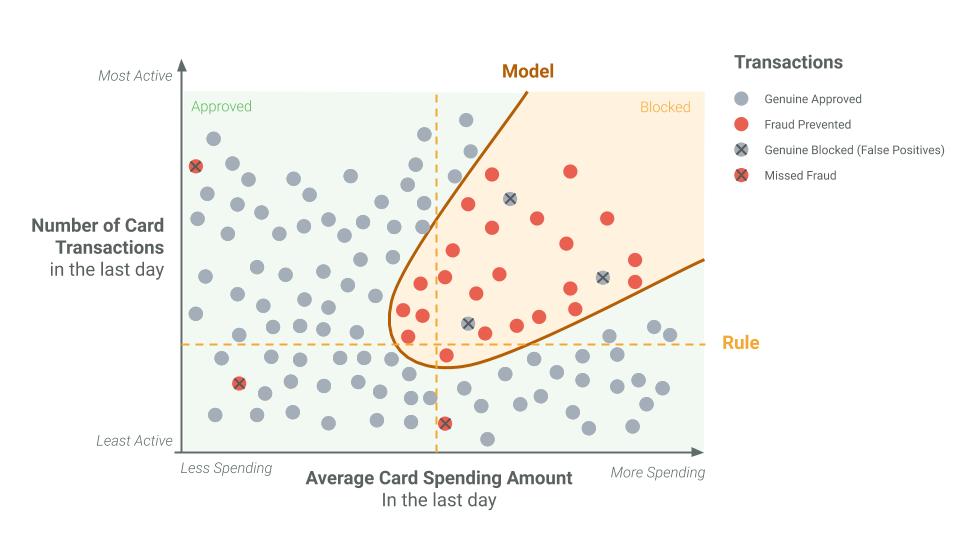
In the two graphs below, we see that a rule will tend to produce a significant number of false positives. At the same time, a rule will also miss fraudulent transactions by misreading them as non-fraudulent. Machine learning, however, can dive into big data sets with a scalpel, not a sledgehammer. Machine learning models enable a significant reduction in false positives while increasing the detection of fraudulent activity.
Please, note that the example depicted below is a simplification. In reality, whereas rules will take into consideration a maximum of 4 to 5 transaction attributes, machine learning models will leverage tens to hundreds of attributes, making the differences in False Positives and True Detected Fraud even more dramatic than in this representation.
How machine learning succeeds where rules fail
 Minimizing Disruption for Legitimate Customers
Minimizing Disruption for Legitimate Customers
Clients of financial institutions want protection against fraud. However, they also do not want fraud countermeasures to interfere with their daily activities. Customers would not be satisfied if, when traveling abroad for the summer vacation, their transactions were blocked due to the fact that they were in a different country. While these events still frequently occur with rules-based systems, machine learning leverages tens to hundreds of attributes of each transaction and can, in turn, identify more subtleties in the data. For example, despite the fact that Jane Doe is in an unusual location, she is staying in a hotel from a hotel-chain that she favors, she continues to have lunch around noon and her average daily spending is only 20% above her typical daily average. The model will pick up this information and more when making a decision.
This ensures that scenarios like the one mentioned previously happen significantly less frequently.
Key Takeaways
Fraud has too many faces; there are too many unique cases to pursue manually. Machine learning leverages tens to hundreds of data attributes, enabling financial institutions to identify pervasive and subtle threats, even when there are changes in context. This would not be achievable through rules-based systems. In addition to augmented fraud detection, machine learning-based systems also learn legitimate behaviors that improve customer experience by reducing the disruption of daily legitimate activities.
Share this article:
Related Posts

0 Comments10 Minutes
Boost the ESG Social Pillar with Responsible AI
Tackling fraud and financial crime demands more than traditional methods; it requires the…

0 Comments8 Minutes
Enhancing AI Model Risk Governance with Feedzai
Artificial intelligence (AI) and machine learning are pivotal in helping banks and…

0 Comments14 Minutes
What Recent AI Regulation Proposals Get Right
In a groundbreaking development, 28 nations, led by the UK and joined by the US, EU, and…